0- 새로운 object를 cluttered environment에서도 충분히 잘 pick and d place한다.
1. Multi-affordance grasping framework
2. A cross-domain image matching framework
전반적인 접근
- robot system은 하나의 물체가 junk로 부터 분리되어있기 때문에, 전방 카메라가 어떤 카테고리의 물체인지 알아내서 어떤 쓰레기통에 넣는지를 결정하는 문제이다.
- 새로운 물체가 감지되었고 그것은 알고있는 알고리즈에 의한 것이 아니다.
- 물체의 크기 범위는 매우 다양하고 다양한 형태의 물체를 다룰 수 있다.
Challenge 1 : plannin ggrasps ith multi affordnce grasphing
- Learning affordances with fully convolutional networks
input : multi-mode, raw data(RGB),
output : a binary probability map representing
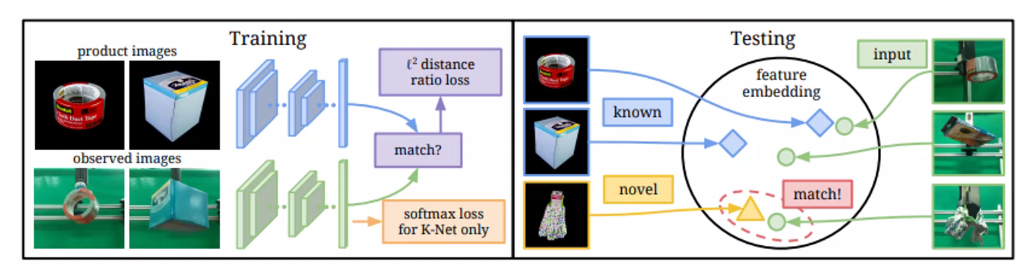
Metric learning for cross-domain image matching
- metric function, candidate product image랑 output distance value를 둘 다 측정해서 어떻게 image가 같은 object인지를 학습한다.
Experiment
물체의 긍정적인 부분은 green, netgative는 red로 둔다.
Amazon Robotics에서 평가를 했다.