Part 1 개요
01 안내서 발간 배경 및 목적
- 생성형 AI와 파인튜닝을 통해 AI를 특정 요구사항에 맞게 파인튜닝하여 잘 맞춤화된 콘텐츠 생성을 할 수 있게 되었다.
- 그러나 데이터 알고리즘 편향으로 인한 잠재적 편견, 차별 및 기본 인권 침해에 대한 우려가 제기되어 이에 대한 합법성, 윤리, 사회적 안전성에 대한 평가 기준을 마련하여 신뢰성을 확보하고자 한다
- 국가와 기업에서 AI 도입의 위험을 완화하고 신뢰할 수 있는 AI 시스템을 구축하기 위해 많은 국제적 요구사항을 통합하여 가이드라인을 제공하고 있다.
< 생성 AI 기반의 서비스를 개발할 때 중요한 신뢰성 고려 사항 이해 도모>
포괄적인 리소스를 통해 생성 AI 및 도메인별 파인튜닝 모델 기반 서비스를 제공하고자 하는 기업과 조직은 신뢰성을 확보함으로 인해 서비스의 경쟁력을 강화할 수 있다. 생성 AI가 우리의 세상을 점점 더 형성해 가는 시대에 신뢰할 수 있고 안정적인 생성 AI 시스템과 서비스를 개발하는 것은 사회 발전과 신뢰 유지를 위한 필수 요소이다
02 생성 AI 신뢰성 동향
생성 AI
- BERT 및 GPT : 대규모 데이터셋에 사전훈련 된 주요 구조를 담당하는 모델
- 파인튜닝 모델 : 특정 작업과 도메인에 맞게 조정하여 관련성을 높이는 모델
⇒ 신뢰성을 높이기 위해 파인튜닝 중 데이터 준비, 모델 편향 완화 등의 과정을 개선해야 한다.
🙌🏼 생성 AI의 견고성(robustness)를 정의
- 다양한 환경에서 일관되고 안전하게 작동
- 적대적 공격(Adversarial Attack)에 대처 가능
- 신뢰할 수 있는 결과 생성 능력
- 유해하거나 혼란스럽고 편향된 콘텐츠를 생성하지 않는 윤리적 완화 작용
2.1 생성 AI 신뢰성 동향
- 견고성과 윤리, 일관성 있게 작동하는 서비스 구축에 집중
- 다양성 보장, 환각 현상 완화를 위한 윤리적 프레임워크 필요
- 모델 절차, 시스템 출력을 제어하고 모니터링하는
⇒ 생성 AI 생태계를 전반적으로 고려해야함
🙌🏼 저작권 및 지식 재작권에 대한 가이드라인 필요
- AI가 생성한 작품의 소유권에 대한 법적 해석 분분
- 미국 저작권청은 AI가 생성한 콘텐츠를 퍼블릭 도메인의 일부로 간주하고 AI를 작성자로 인정하지 않는다 함
- 아티스트들은 자신의 작품이 동의없이 학습에 이용되어 저작권 침해 소송을 진행 중
2.2 생성 AI 활용 영역
- 텍스트, 이미지, 오디오 합성 데이터 등 다양한 종류의 컨텐츠 활용에 쓰임
1 콘텐츠 생성
2 정보 분석 : 정보 분류 • 평가 검색
3 정보 추출 : 추출, 향상, 인식, 세분화, 이미지 융합, 큐레이션, 요약
4 콘텐츠 향상 : 대비 향상, 이미지 편집, 업스케일링, 복원, 콘텐츠 개인화
5 사용자 지원 : 지능형 어시스트턴트, 챗봇, Q/A 봇 등 사용자 경험 향상
2.3 생성 AI 이슈 사례
- 윤리 및 신뢰성
- ‘AI 신뢰성: 원칙에서 실무까지’[2] - 연구 및 개발 모범 사례에 대한 인사이트 제공
- AI 윤리 프레임워크 개발
- 교육 및 연구 분야의 생성 AI에 대한 지침 제공, 규정
- 생성 AI의 위험 관리
- 명확한 윤리적 지침에 따라 설계 • 배포하지 않으면 위험에 처할 수 있는 점을 강조
- 콘텐츠 제작 및 사람의 협업
- AI가 제대로 된 인식과 정서적 이해가 부족한 컨텐츠 생성할 수 있고, 저작자, 독창성, 권리에 대한 윤리적 문제 발생 가능
- 사람의 개입으로 품질을 평가 및 트렌드 반영을 위한 인간의 개입은 보편화 됨
- 생성 AI 시스템에 대한 법적 소송
- 이미지 제작 업체 Getty에 대해 이미지 학습에 대한 저작권 위배
- Anderson VS Stability AI Ltd. 유사성
- 마이크로소프트, Github, Openai 저작권이 있는 소프트웨어를 사용자가 침해할 수 있는 코드를 생성하도록 허용하여 지식재산 기본법을 위반했다고 주장
- 환각 출력 및 영향 확인
- Avianca, Inc. Gen AI 법정에서 환각 결과물을 사용한 사례
⇒ 시스템 사용에 대한 영향을 파악하여 국내에서 생성 AI 모델의 신뢰성을 높이기 위한 연구
- [경제 영향 연구] AI 기술이 어떻게 노동력과 경제에 긍정적인 영향을 미칠 수 있는지
- [AI 생태계 개발] 학계-산업계-정부가 협력 중
- [윤리적 AI 문제] 전문가들이 무분별한 사용에 대한 조언함
2.4 생성 AI 신뢰성 정책 및 연구 동향
- 생성 AI 시스템이 책임감 있게 사용되고 잘못된 정보나 유해한 컨텐츠를 전파하지 않도록 보장하는, 명확한 정책과 규정이 필요
- 방법론에 대한 연구, 환각 현상을 줄이는 연구, 정확성과 신뢰성이 높은 컨텐츠 제작 연구
- 오류로 인한 피해, 설명이 필요한 애플리케이션에 사람 없이 통합하는 것을 주의
- AI와 인간의 전문성의 조화를 이뤄야함
대표성과 다양성을 갖추고, 「개인정보 기본법」 제정에 따른 자율 기구의 구성으로 개인정보보호를 고려한 ‘학습용 데이터’의 품질, 복잡한 작업을 효과적으로 처리할 수 있는 ‘컴퓨팅 성능’, AI 생성 콘텐츠를 감독할 수 있는 ‘충분한 인력’ 등이 확보되어야 한다

03 안내서 마련 방법
- 인력 : 학계와 업계에 종사하는 도메인 전문가, 연구자, 산업계 실무자, 법률 전문가의 집단적 지혜와 공동의 노력
- 제작 과정 : 인공지능 및 생성 AI 서비스 전문 기업과 교류, 협업을 통한 포괄적 사례 연구 수집 및 피드백을 거쳐 실무 활용도 높임
3.1 인공지능 신뢰성 프레임워크
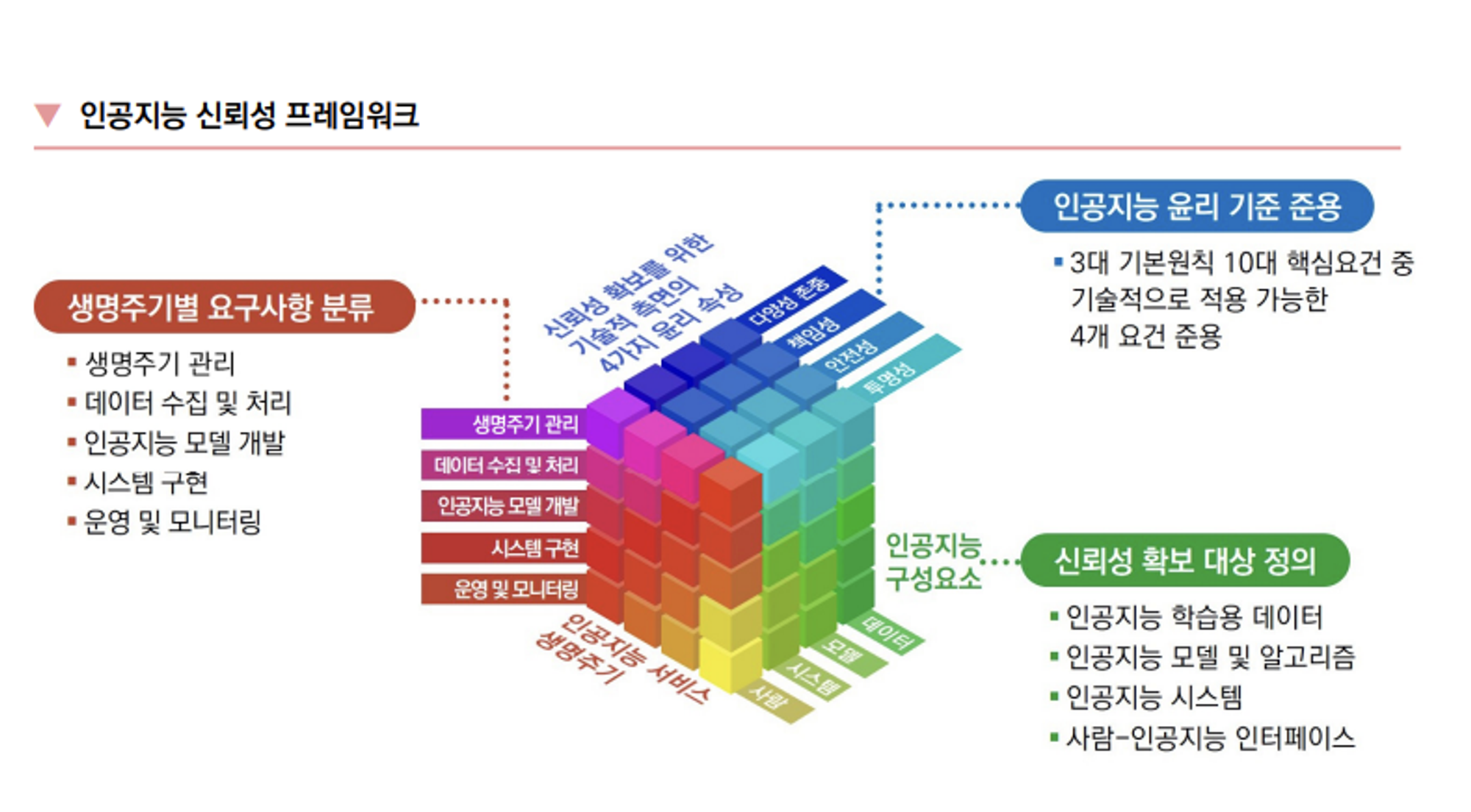
- 인공지능 구성 요소 - 신뢰성 확보 대상 정의
- 인공지능 학습용 데이터 : 학습, 추론에 활용되는 데이터의 편향성 배제 검증
- 인공지능 모델 및 알고리즘 : 안전한 결과를 도출, 설명 가능성, 악의적 공격에 견고한지 검증
- 인공지능 시스템(HW, SW) : 모델 및 알고리즘이 적용된 전체 시스템을 대상으로도 제대로 추론가능한지, 잘못 추론한 경우에 대한 대책이 존재하는 지 검증
- 사람-인공지능 인터페이스 : 사용자가 시스템 동작을 쉽게 이해할 수 있으며, 오작동 시 사람에게 알림 혹은 제어권 양도가 가능한지
- 인공지능 서비스 생명 주기 - 생명주기별 요구사항 분류
- 생명주기 관리 : 시스템 관리 감독, 위험요소 분석 및 대응방안
- 데이터 수집 및 처리 : 품질 확보, 라벨링 및 특성 문서화
- 인공지능 모델 개발 : 목적에 따른 구현, 성능평가
- 시스템 구현 : 문제 발생 대비 안전 모드 구현 및 알림 절차 수립
- 운영 및 모니터링 : 모델 재학습을 통한 성능 보장, 편향 탐지, 공평성, 설명가능성 등 신뢰성 모니터링, 문제 발생 시 해결방안 마련
- 인공지능 신뢰성 특성
- 인공지능 윤리 기준을 기반으로 ‘다양성 존중’, ‘책임성’, ‘투명성’ 도출
[출처]
[1] 과학기술정보통신부・한국정보통신기술 협회 《2024 신뢰할 수 있는 인공지능 개발 안내서 – 생성 AI 기반 서비스 분야》’
[2] Li, Bo, Peng Qi, Bo Liu, Shuai Di, Jingen Liu, Jiquan Pei, Jinfeng Yi, and Bowen Z., "Trustworthy AI: From principles to practices," ACM Computing Surveys, vol. 55 no. 9, pp. 1-46, 2023
'AI Engineering Topic' 카테고리의 다른 글
| What is pyproject.toml file for? (0) | 2023.07.19 |
|---|---|
| 페이퍼 프리뷰의 리뷰 KoLLaVA : Korean Large Language and Vision Assistant (Visual Instruction Tuning) (0) | 2023.07.11 |
| 보이저엑스 딥러닝 질문 답변 with ChatGPT (0) | 2023.05.09 |
| 보이저엑스 개발자 인턴 기술 질문 대답 준비 with ChatGPT (0) | 2023.05.09 |
| Excel파일에서 Datafrmae으로 to_dict 딕셔너리만들기 (0) | 2022.11.23 |